Our argument
What is an AI agent?
In traditional AI, agents are defined
entities that perceive and act upon their environment. In the LLM era,
the term is
used in a narrower way (a thermostat would qualify as an agent under the traditional definition). Researchers
have tried
to formalize the community's intuitive understanding of what constitutes an agent in the context of
language-model-based
systems. Many of them view it as a spectrum — sometimes denoted by the term 'agentic'
— rather than a binary
definition
of an agent. We agree with this perspective.
We identify three sets of properties that cause an AI system to be considered more agentic according to
existing
definitions (Shavit et
al.
2023, Chan et al. 2023, Gabriel et al. 2024, Weng 2023, Chase 2024):
- Environment and goals. The more complex the environment, the more AI systems operating in that environment are agentic. Complex environments have a range of tasks and domains, multiple stakeholders, a long time horizon to take action, and unexpected changes. Systems that pursue complex goals without being instructed on how to pursue the goal are more agentic.
- User interface and supervision. AI systems that can be instructed in natural language and act autonomously on the user's behalf are more agentic. In particular, systems that require less user supervision are more agentic. For example, chatbots cannot take real-world action, but adding plugins to chatbots (such as Zapier for ChatGPT) allows them to take some actions on behalf of users.
- System design. Systems that use tools (like web search or code terminal) or planning (like reflecting on previous outputs or decomposing goals into subgoals) are more agentic. Systems whose control flow is driven by an LLM, rather than LLMs being invoked by a static program, are more agentic.
Our Findings
We present five key findings from our analysis of AI agent benchmarks and evaluations.
1. Cost-controlled evaluation is necessary
Simple baselines can outperform complex agents
The language models underlying most AI agents are stochastic. This means simply calling the underlying model multiple times can increase accuracy. We show that such simple tricks can outperform complex agent architectures on the HumanEval benchmark, while costing much less. We argue that all agent evaluation must control for cost. (We originally published this finding here.)
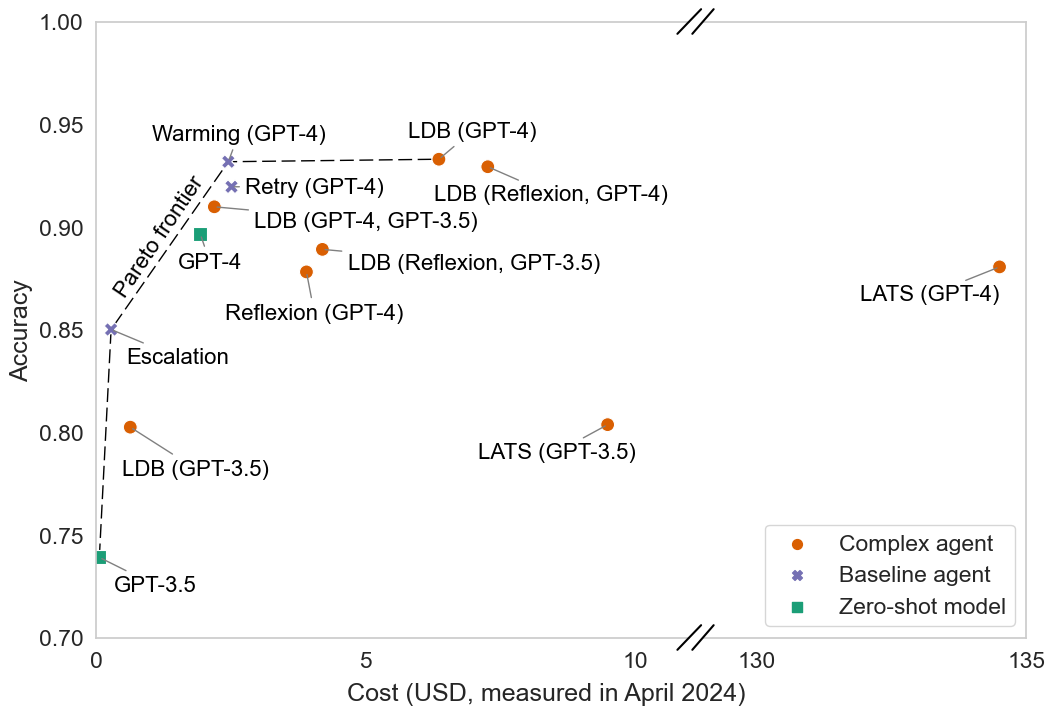
Our simple baselines offer Pareto improvements over SOTA agents. We run each agent five times and report the mean accuracy and the mean total cost on the 164 HumanEval problems. Where results for LDB have two models/agents in parenthesis, they indicate the language model or agent used to generate the code, followed by the language model used to debug the code. Where they have just one, they indicate that the same model was used to both generate the code and debug it. Note the nonstandard axes; In the Appendix of the paper, we show our results with the full y-axis as well as error bars and provide additional details. We also include robustness checks and explains why we measure dollar costs instead of using proxies for cost such as the amount of compute used.
2. Jointly optimizing accuracy and cost yields better agents
Optimizing both accuracy and cost offers a promising new direction for building more efficient and practical AI agents
Visualizing evaluation results as a Pareto curve of accuracy and inference cost opens up a new space of agent design: jointly optimizing the two metrics. We show how we can lower cost while maintaining accuracy on HotPotQA by implementing a modification to the DSPy framework.
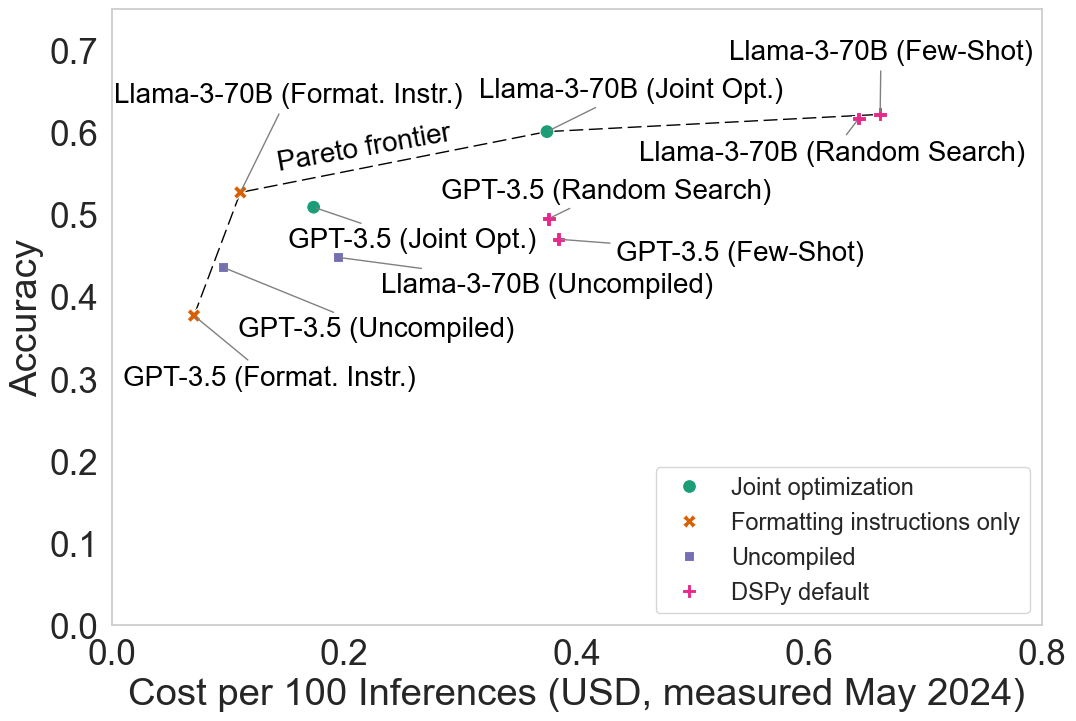
Joint optimization maintains accuracy while significantly reducing cost. All measurements are averages of 5 runs on the test set. A figure with error bars and other details about our empirical results are included in the Appendix of the paper. Note that DSPy has a much higher cost than our baseline agent designs since it always includes up to 8 few-shot examples per prompt (the number being a configurable parameter) without optimizing for cost, whereas the baseline agents include none, and joint optimization uses a variable number of examples.
3. Model and downstream developers have distinct needs
Model evaluation benchmarks can be misleading for downstream users
AI evaluations serve at least two distinct purposes. Model developers and AI researchers use them to identify which changes to the training data and architecture improve accuracy. We call this model evaluation. And downstream developers, such as programmers who use AI to build consumer-facing products, use evaluations to decide which AI systems to use in their products. We call this downstream evaluation. The difference between model evaluation and downstream evaluation is underappreciated. This has led to much confusion about how to factor in the cost of running AI. Through a case study of NovelQA, we show how benchmarks meant for model evaluation can be misleading when used for downstream evaluation. We argue that downstream evaluation should account for dollar costs, rather than proxies for cost such as the number of model parameters.
4. Agent benchmarks enable shortcuts
Overfitting and lack of holdout sets mislead downstream users
We show that many types of overfitting to agent benchmarks are possible. We identify 4 levels of generality of agents and argue that different types of hold-out samples are needed based on the desired level of generality. Without proper hold-outs, agent developers can take shortcuts, even unintentionally. We illustrate this with a case study of the WebArena benchmark.

Appropriate holdouts based on level of generality. The majority of benchmarks do not include an appropriate held-out set, including 7 that have no hold-out and no indication that a holdout set will be added in future editions of the benchmark. See the paper for more details.
5. Agent evaluations lack standardization and reproducibility
Inconsistent evaluations lead to inflated accuracy estimates
We found pervasive shortcomings in the reproducibility of WebArena and HumanEval evaluations. These shortcomings stem from three distinct (but related) reasons. First, as of yet, there are no clear standards for providing agent evaluation scripts. As a result, the differences between model and agent benchmarks are not appreciated. Finally, due to the lack of community norms on evaluation, there is scope for bugs to creep in during agent development and evaluation. We include examples and more details on each in the paper. Shortcomings with standardization have also been observed for LLM evaluation. Evaluation frameworks like HELM and LM Evaluation Harness address these shortcomings for model evaluations by providing standardized evaluation results. But as we have seen, these frameworks don't suffice for evaluating AI agents. Developing an agent evaluation framework is a ripe area for future work.
Conclusion
AI agent benchmarking is new and best practices haven't yet been established, making it hard to distinguish genuine advances from hype. We think agents are sufficiently different from models that benchmarking practices need to be rethought. In our paper, we take the first steps toward a principled approach to agent benchmarking. We hope these steps will raise the rigor of AI agent evaluation and provide a firm foundation for progress.
Acknowledgments
We thank Rishi Bommasani, Rumman Chowdhury, Omar Khattab, Percy Liang, Shayne Longpre, Yifan Mai, Morgan McGuire, Matt Salganik, Hailey Schoelkopf, and Venia Veselovsky for discussions and inputs that informed our analysis. We are grateful to the authors of the papers we engage with for their quick responses and for sharing their code, which makes such reproduction analysis possible in the first place. In particular, we are grateful to Karthik Narasimhan (Reflexion), Paloma Sodhi and Yoav Artzi (STeP), Cunxiang Wang and Ruoxi Ning (NovelQA), Zilong Wang (LDB), and Andy Zhou (LATS), who gave us feedback in response to an earlier draft of this paper. We acknowledge compute support from Princeton University's Center for Statistics and Machine Learning and OpenAI's researcher access program.